Once upon a time, a system administrator decided to become a DevOps. Diligently engaged in self-education and played іn sandbox with docker and python. He tried to learn a piece of basic knowledge to get a dream job.
The day came, and he posted his resume on all HR platforms. Oh, miracle! One company noticed him and invited him for an interview. The system administrator dressed up nicely. He repeated everything he had taught, smiled, and went to the interview.
On the way to the appointed place, he imagines how he already works as a DevOps engineer. How he uses IaaC on daily basis to the fullest and raises production in Kubernetes because automation is everything. But much to his dismay, this was not the fairytale case.
Here he sits in a meeting room, communicates with the interviewer, and answers the following questions:
I: Do you know docker?
SA: I have theoretical knowledge and did "this" and "that" things. I want to develop in this direction more in a professional way.
I: No one will teach you here. After work, you can stay and study for another 3-4 hours.
SA: Oooooh. - answered the system admin.
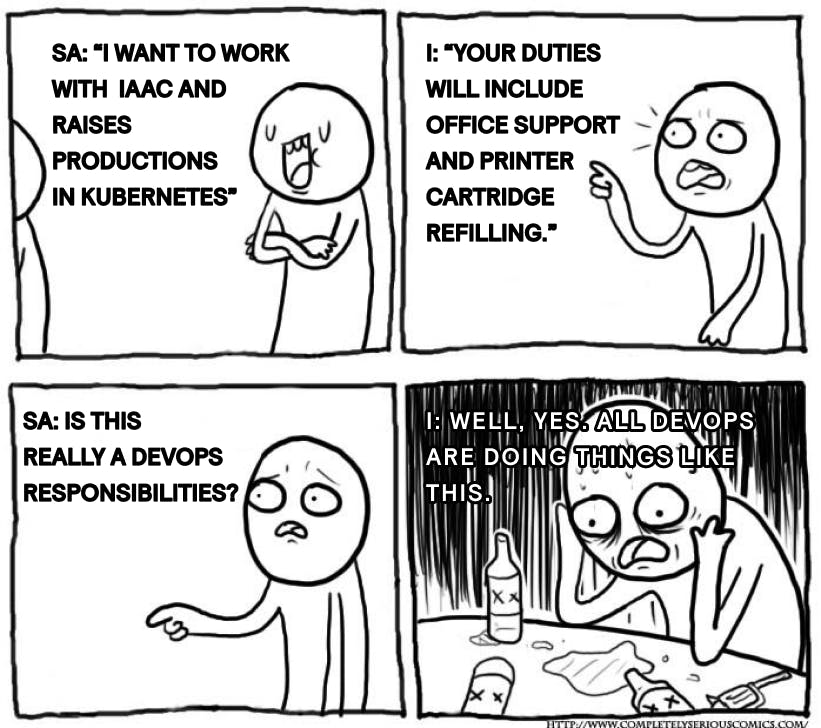
I: Your duties will generally include office support and printer cartridge refilling.
SA: Is this really a DevOps responsibilities?
I: Well, yes. All DevOps are doing things like this.
After 20 minutes of this interview, the System Administrator, full of earlier hopes, ran away from this place as quickly as he hadn't ever before in his life.