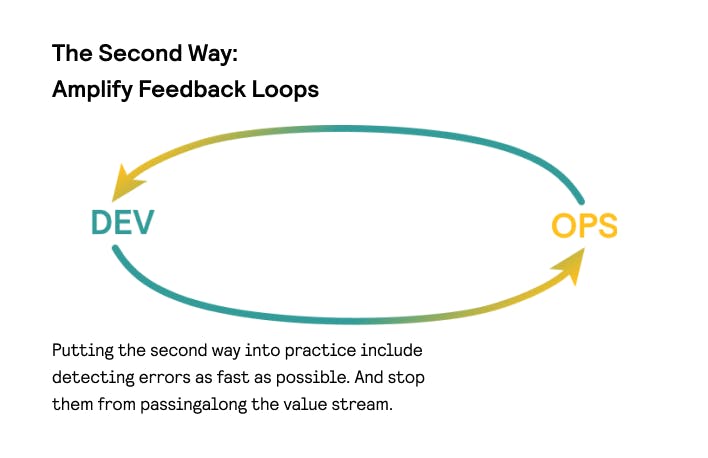
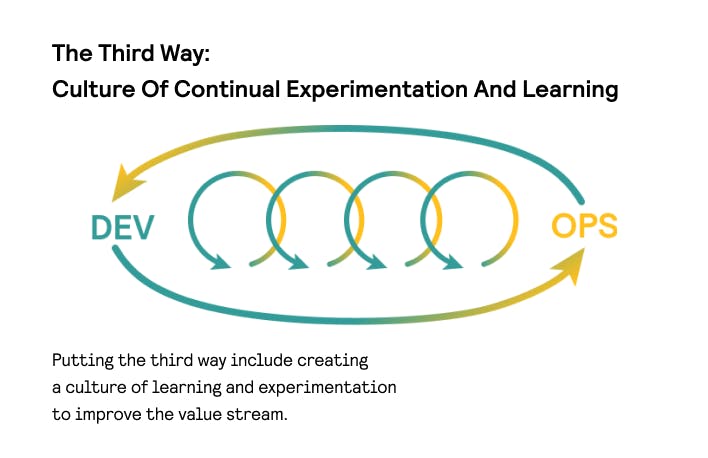
In the technology value stream, work typically moves from the left (Development) to the right (Operations) side, from the conception of the feature to its deployment in production.
According to Gene Kim’s Principles of Flow, mature DevOps organizations overcome this route in the fastest way possible, delivering value to their customers quickly. Lead Time—the total time between the request from the business to the functionality deployed and available in production to the customer—is the key metric here. To keep it to a minimum, you should have a lean and consistent project delivery pipeline. Here’s how you can achieve this.
Reduce the size of your work batches
In software development, a batch is a piece of work that moves between 3 stages, such as development, testing, and deployment. In waterfall development, where the batches are huge, weeks or even months of persistent work separate these stages. Too often, serious bugs made at the beginning of development are discovered only during deployment when release is looming over the horizon.
This can be easily avoided if you shrink your batches, meaning that even the smallest change your team commits to the version control system is integrated, tested, and deployed. Case in point, Amazon does at least 50 million deployments per year (the estimation was made back in 2014, that’s why “at least”)—the principle of small batches in action! As a result, they don’t stumble upon critical bugs that affect the entire solution late in the development process.
If problems arise, they are easier to fix, sparing development teams from the technical dept in the future.
No doubt, keeping your work batches small isn’t that easy. There are still lots of dependencies that can slow down the work. For example, you may have all tests running for each PR. Or the build time can time a while if you use Java or similar languages. Or you are updating resources using AWS CDK can also make things slower. But in any case, the main idea here isn’t making small batches where it’s impossible. It’s more about the mindset and helping your developers overcome the old era of “wait-till-Thursday-and-push-all.”
Limit work in process (WIP)
This rule is closely related to the previous one: large batches equal a large number of undone tasks. As a result, when problems arise (and they always arise in the development process), they break your processes: you have to rush between multiple unplanned tasks, getting into prioritization traps. In this case, technical debt is just inevitable.
Avoid multitasking to prevent a catastrophe resulting from such a regular thing as problems during development. “Stop starting, start finishing,” as the Kanban method states. This means: instead of adding a new task, think twice. Maybe, there’s something that needs to be done? It’s easier to control a smaller number of tasks, after all. And if the delay is happening, try to figure out why.
Give visibility
You can’t control what you don’t see. If you don’t know who is responsible for what, it’s impossible to control and limit your WIP. Unfortunately, visibility can be challenging in software development, where work can be done or reassigned to the other team with a click.
To achieve the needed level of visibility, you can use kanban boards where work is presented on cards, moving from the left to the right based on its status. Thus, everyone involved in the project can see which tasks are currently in progress at each phase, where everything goes smoothly, and where the work gets stalled. Besides, the tasks become easier to prioritize, manage (you can assign and reassign them to the other team), and measure, increasing your market speed.
Reduce handoffs
Throughout the development process, the work moves from one contributor to the other, from one department to the other, for functional testing, environment creation, server administration, networking, and other tasks. Each handoff requires clear communication, ticket creation, scheduling, prioritization, and so on, potentially creating delays that remain the top constraint to successful project completion.
So, your task is not just to make each handoff seamless. You should also reduce the number of times the work is passed between team members. This can be achieved through reorganizing teams and automating processes. For example, Etsy automated its deployments with the help of Deployinator—a tool that offers one click-deployments. As early as 2015 (!), it helped them deploy code about 40 times a day.
But how should you reorganize teams to reduce the number of handoffs? Build smaller teams comprising a few developers, a QA expert, and an operations engineer like successful companies do. It helps them remove silos and thus avoid unnecessary handoffs and eliminate the it-works-on-my-machine situations.
So, whether you are a startup or a big enterprise with multiple departments, it’s important easy to stick to this everyone-works-with-everyone setup. Or if you are too big for this arrangement, you should at least monitor the communication between departments.
Eliminate waste
In DevOps, waste is any action that doesn’t bring value to the development process and just hinders the workflow. It can be anything: manual work that can be automated, monolithic infrastructure that interrupts the flow, tools that are never used, unnecessary features in a product, unfinished work, incomplete documentation, motion waste (resulting from too many handoffs), and beyond. So, you have to identify and remove those bottlenecks from the value stream to make the process more efficient.
You may read and wonder, how can I make sure in the cloud setup that, say, some manual work is done? Well, in one of our projects, we restrict any CRUD-type operations on the infrastructure unless User-Agent is Terraform. It took few months for people to get used to it, but believe us, it’s worth waiting.
Hunt your constraints down
Eliminating the system’s constraints will help you considerably reduce waste. Based on our experience the most common things, teams might be dealing with the following ones:
- Environment. You can’t deploy code on-demand since creating the needed environment takes weeks or months. A countermeasure can be self-sufficient environments available to you whenever necessary.
- Manual deployments. You can’t deploy fast since you do it manually, or the process involves 1,500 error-prone, manual steps. Automated deployments can be the way out. It may sound crazy at first, what we usually do is try to make automated deployments according to the following schedule: first, once a week; then, once in 3 days; and so on (based on how it goes.) This allows the upper management to get used to the schedule and see all the benefits.
- Manual testing. You can’t deploy fast because each deployment requires setting up a test environment from the ground up, which can take weeks. You need to automate your tests. Without this, the tip above is useless. Yes, automation engineers cost more money, but there is a reason for that: if you have your tests automated and code deployed more often, you are far ahead of your competitors in terms of improving your product
- Tight architecture. Every change made in your code affects the entire system, making any update a challenge and blocking fast deployments. That’s why you need to go for a more flexible architecture. If you look at every successful DevOps journey, it begins with migration to the cloud and microservices architecture.
Once you identify a constraint, you need to figure out how to eliminate it, then actually eliminate it, scan your system for other constraints afterward, and repeat the process if necessary.