The 2020 DevOps Trends Survey shows that over half of responders leverage DORA metrics. These DevOps metrics include deployment frequency, lead time for changes, mean time to recovery, and change failure rate.
But these four indicators do not cover all aspects of your DevOps initiatives. That's why we added some extra measurements to our list.
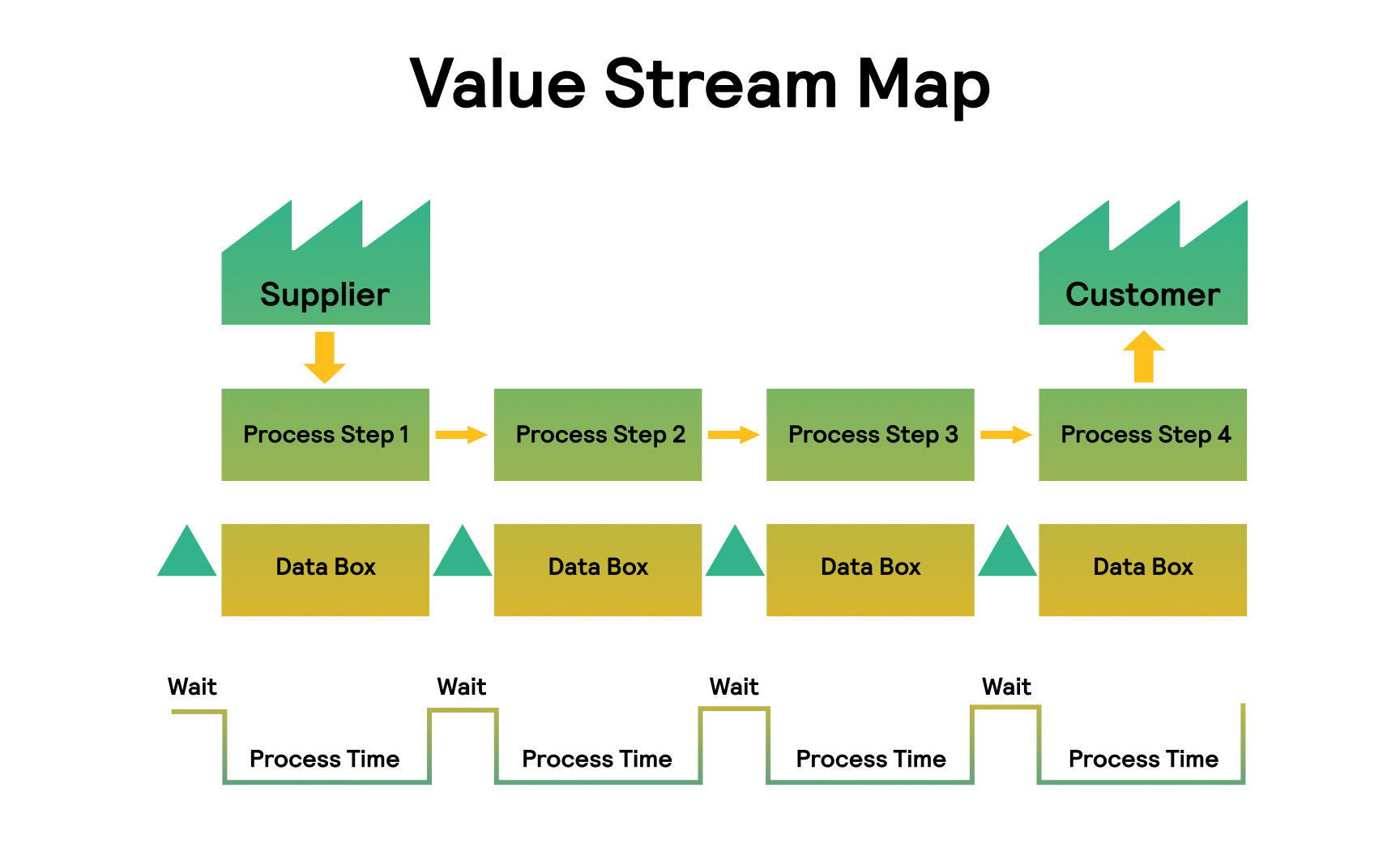
Deployment frequency
Deployment frequency (DF) shows how often you deploy the code to production or release it to end users. This metric is used to gauge the efficiency of your DevOps engineers and operations teams. Some companies also include delivery frequency, which measures how often your team releases code changes into a pre-production staging environment.
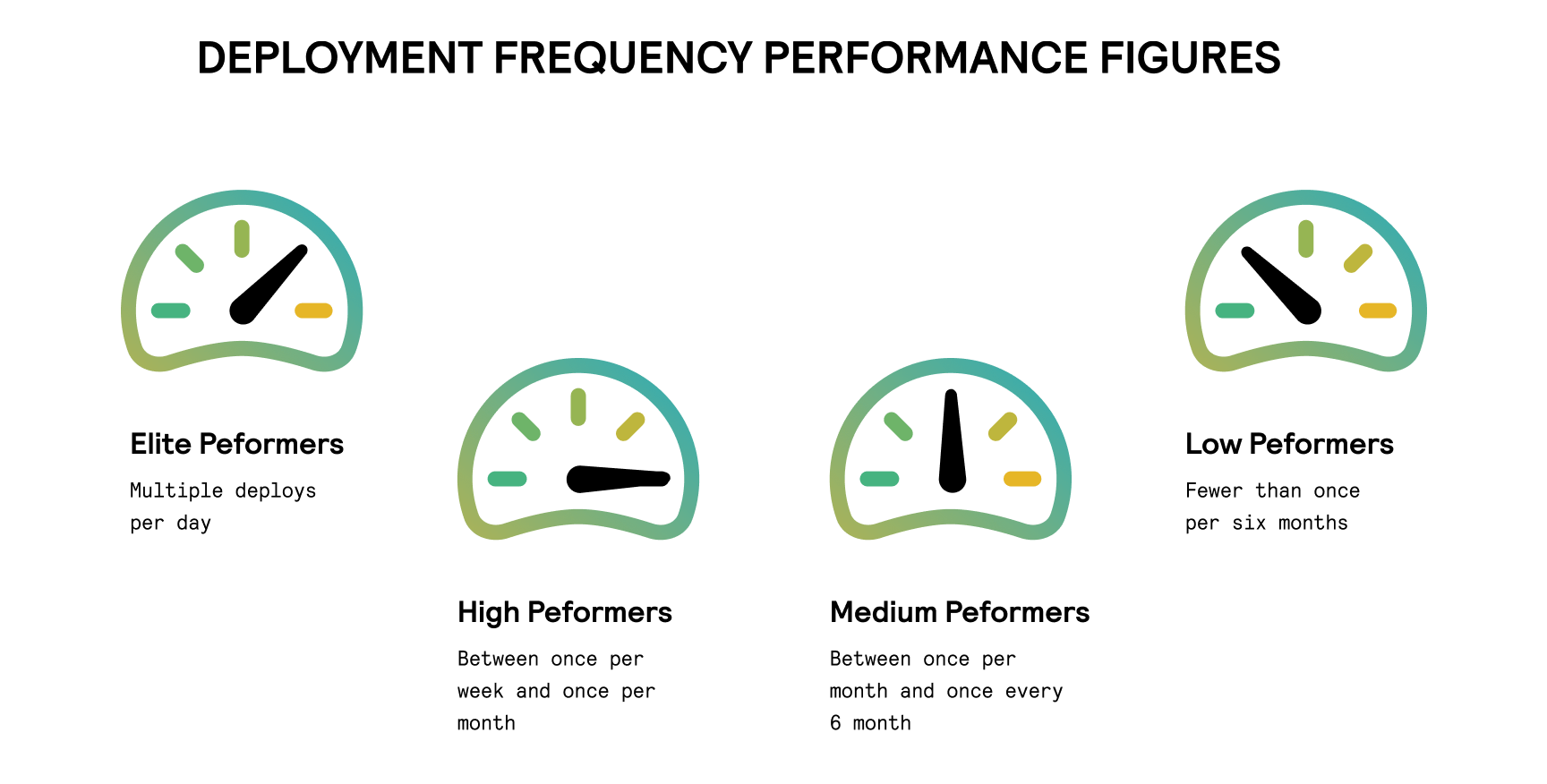
The best practice is to deploy code consistently in smaller batches. This leaves less room for error and makes it easier to identify bugs before they escalate. According to Accelerate’s 2021 State of DevOps Report, top teams deploy code multiple times a day (or around 1,460 times per year). DFP in less efficient teams can range from once a month to a single deployment every six months.
To measure DFP accurately, you first need to define a successful deployment. For example, you may need to adjust the DevOps metrics dashboard to factor in all operational deployments or those generating a specific amount of traffic.
If we put aside giants like Etsy or amazon, with dozens deployments per day. As it was said before - the most frequent scenarios are to deploy once a day on average. It’s also needed not for the speed of delivery. But to eliminate fear of your engineers to deploy so often
Lead time for changes
Lead time for changes (LT) is a DevOps metric that measures the velocity of software delivery. It shows how long your team implements, tests, and delivers code after committing to a code change.
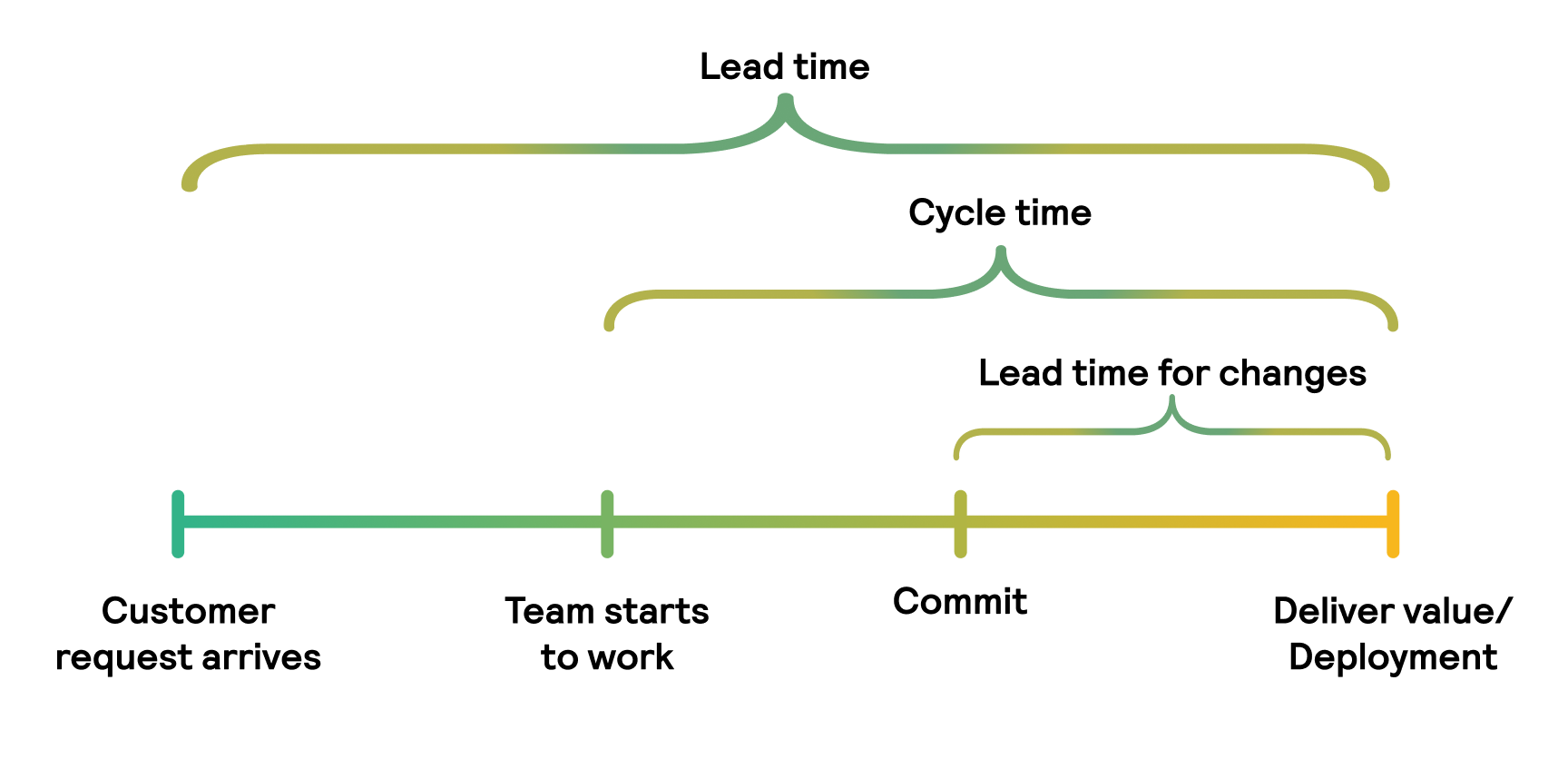
Elite DevOps practitioners strive to change code in less than an hour. But in most cases such often releases are not necessary and require huge budgets to be spent on this direction. High-performing teams spend from one day to one week delivering a successful production change. Longer lead times may indicate that developers work on separate branches and neglect DevOps automation tools for testing and quality control.
Recording the start and the end of any code changes is crucial to gauge these metrics properly. You should also measure the volume of changes for deployments, so you can focus only on impactful updates that affect your business performance.
Change failure rate
Change failure rate (CFR) is the percentage of code changes that need hotfixes, rollbacks, patches, or other remediations. To calculate it, you must divide the number of deployment failures by the total number of deployments. However, it doesn’t account for failures your team detects and fixes before deploying code. This metrics allows you to understand how much effort you need to put into your testing capabilities and how comfortable your engineers are with deploying the code even if it may have issues in the early stages.
Unlike other DevOps metrics and measurements that show software delivery speed, CFR lets you understand the quality of your end product. Lower rates mean that your teams can identify bugs early in development, which equals less money and time spent to fix them. To earn a badge of an elite DevOps team, try to keep the change failure rate below 15%.
Defect escape rate
The defect escape rate helps you understand how many bugs make it to end-users. To measure it, you must divide the number of bugs found in production by the total number of bugs found during the entire software development life cycle.
This metric reveals cracks in your development pipeline. It is also tightly linked to end-user satisfaction rates, as a significant portion of issues will be detected by analyzing user feedback and customer support tickets.
This measurement also helps companies put things into perspective. You might think that finding fifteen bugs after deployment is way too much. But it may be a good result if that’s only 2% of all issues found during the development.
If you combine this metric and LT metric, it will be interesting to see the corelation between faster releases and how much more or less errors (usually more) sneak into release. If you have additional budget, or in case you are Head of Engineering and want to have some arguments for your financial deparment about why you need ot switch from manual to automated testing, or why you need invest more into testing - this may be very useful for you.
Mean time to recovery
Mean time to recovery (MTTR) shows how fast you bounce back from partial service interruptions and total system failures. To calculate it, take the time it took you to fix the bugs and divide it by the number of issues fixed in a given period.
Shorter MTTR encourages engineers to experiment and eliminates fear of making changes. It usually takes DevOps professionals less than a day to fix an issue, whereas top performers can restore services in under an hour. Remember we mentioned resiliency in previous metrics? That’s what we meant.
Your ability to fix issues depends on how fast you can detect them. That’s why nearly 50% of DevOps professionals use up to five monitoring tools, based on GitLab’s 2021 DevSecOps Survey. Additionally, 72% prefer software that feeds developers and operations teams with real-time metrics.
Engineering reliability
Engineering reliability measures operational performance, system availability, network latency, and application performance index. It shows that your teams can meet your business goals and user expectations.
You must define reliability in terms of user expectations (especially those outlined in the Service Level Agreement) and incorporate reliability principles into the software development life cycle. For example, globally available services, where 0.01% of availability translates to hours of unplanned downtime and million-dollar losses, usually focus on server uptime. Other businesses might prioritize application response, as it affects user experience.
The Accelerate 2021 report found that companies focusing on engineering reliability get bigger benefits from DevOps. Among other things, teams who excel at modern operational practices are 1.4 times more likely to improve their software operational performance and have 1.8 more chances to get better business outcomes.
Knowing what to measure is only half the solution. You should also understand how to extract and transform data from your software development environment.