25 months
Adoption length
25 months
Adoption length
8 Juniors
Participated in our research and workflow optimization
~10 000$
Already saved on operational expenses
Veni (Background and Challenge)
During the process of the workflow optimization, we'd noticed aninterestingrate of mistakes that our employees used to make in their work. A deep analysis of the performance showed that we were losing about 15% of the income correcting mistakes or finding out the reason why this or another situation happened, because we could not let ourselves to solve our inner problems at the clients' expense.
As a result, we decided to sort out the mistakes by their type and find their root cause. Based on the results of our analysis, we managed to make up a plan and a pool of tasks for further workflow optimization.
Vidi (Investigation)
We asked our employees to duplicate their tasks on different projects in our internal Jira. Thus, even though we spent the company's money on keeping the internal Jira up-to-date, it gave us an opportunity to collect precious statistical data that we could use for our further analysis.
We sorted out all the tickets with "bug" type, as well as all those tickets that were Rejected for any reason. After a long manual study of the tickets, we identified the following main reasons of incidents and mistakes made by our employees:

Vici (solution). Learn how we managed to fix these issues.
Knowledge Transfer issues.
he simplest solution that comes to mind would be to force people to hand over project and status details when leaving the project. However, this is not always possible.. Consequently, we had to figure out how to provide a transfer at any time.
As a result, we decided to borrow the solution from the "Dev" part of our component.
We always suggest our clients to adopt the Infrastructure-as-a-Code concept wherever it's possible. Terraform, CloudFormation, Ansible, Chef ... Each of them allows you to describe the infrastructure in a more comprehensive way and much more efficiently than with the help of a regular documentation. We decided to implement Code Styling in Alpacked and clearly define the company's standards for all the main IaaC tools we work with. As an example: Ansible inventory always needs to be divided into the following strict hierarchy: environment type, cloud type, purpose. It has to have an explicitly specified path to keys, python version and a brief comment about host purpose.
| Before | After |
|---|---|
[prod] Host1 Host2 … HostN [dev] Host3 Host4 In this case we see a real lack of information. | [all] production development [production:children] prod-aws prod-gcp [prod-aws:children] prod-frontend prod-backend prod-ci [prod-ci] # Jenkins Slave1 that is used to build some stuff Host1 ansible_ssh_private_key_file=private_keys/key ansible_python_interpreter=/usr/bin/python2.7 [prod-frontend] # A nodeJS instance for frontend with SSR Host2 ansible_ssh_private_key_file=private_keys/key ansible_python_interpreter=/usr/bin/python2.7 [dev:children] dev-aws dev-gcp [dev-aws:children] dev-frontend dev-backend dev-ci [dev-frontend] # A nodeJS instance for frontend with SSR Host2 ansible_ssh_private_key_file=private_keys/some-dev-key ansible_python_interpreter=/usr/bin/python2.7 Host3 |
This way a new person should only know that the project uses ansible for IaaC. It is enough to open the inventory that will tell him about the underlying infrastructure, it's purpose, number of hosts, used clouds and hosts purpose. No more struggling to figure out what is hosted, where, why and how
Experience issues
All experience issues can be devided literally by 2 types:
Emergency issues
In Alpacked, besides technical skills we strive to develop and improve skills needed for effective management and HR operations.
We were impressed by the Site Reliability engineering book by Google. They define an idea of Incidents reports there which we tried to adopt in Alpacked.
Now every mistake is an incident - we consider it as a case instead of blaming an employee. We try to determine the root cause of the incident, the type of employee involvement; the way in which he reacted on the incident, what kind of technical means were used to fix the issue. As soon as the analysis is completed, we proceed to the next step.
We were lucky enough to get familiar with a series of books written by Jocko Willink and Leif Babin. The Dichotomy of Leadership is one of my favorites. One of the chapters stated the idea of the importance of a balance between clear standards and will for creativity. The main idea is that everybody needs to have an ability to independently solve issues, however, in case of unexpected emergency situations, it is recommended to refer to the previously created Standard Operating Procedures.
An adoption of this idea in Alpacked resulted in the following process: once analysis in step A is done and all the factors are investigated, the case is turned into an SOP.
For example, one of our e-commerce clients once got hacked. We found that out during a scheduled audit and first of all we tried to remove all outcomes of that break-in to stop the leak of the customer's data. During this process all the code/infrastructure changes done by hacker got wiped out, which made incident investigation totally impossible. As a result, we created the following security incident SOP:
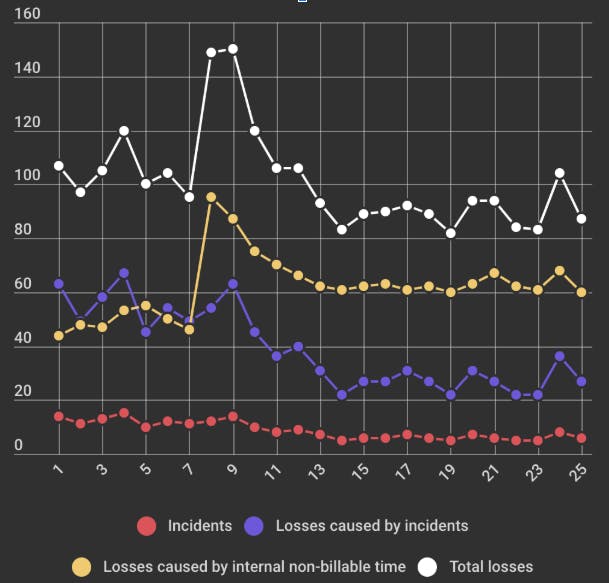
This graph presents an analysis of the results of the implementation of the described practice. Here you can see 4 time dependency functions:
The period from the 1st to the 7th month shows the state of the losses and incidents prior to the implementation of the described methods.
Average number of incidents: 12.3, Average loss rate: 104.2.
Over the next few months, a record amount of time was spent on the implementation of these processes, as well as documentation creating, SOPs, etc.
After this point, it is easy to notice the Total Losses tendency to decrease due to the better ratio of the number of incidents to internal time. Re-phrasing, we can say that our experience has shown that an increase of the amount of internal time required to implement the methods described above ultimately leads to the losses decrease, and consequently, an increase in profits in the long term.
As you can see, we could not reduce the number of incidents to zero or a near zero value. We believe that it is caused by the randomness of some incidents that cannot be foreseen and prevented. Nevertheless, the level of incidents that we were able to achieve seems to be good enough for small and medium-sized IT companies to spend resources on its implementation.
Just fill the form below and we will contaсt you via email to arrange a free call to discuss your project and estimates.









.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max&q=75&w=800&h=533)




