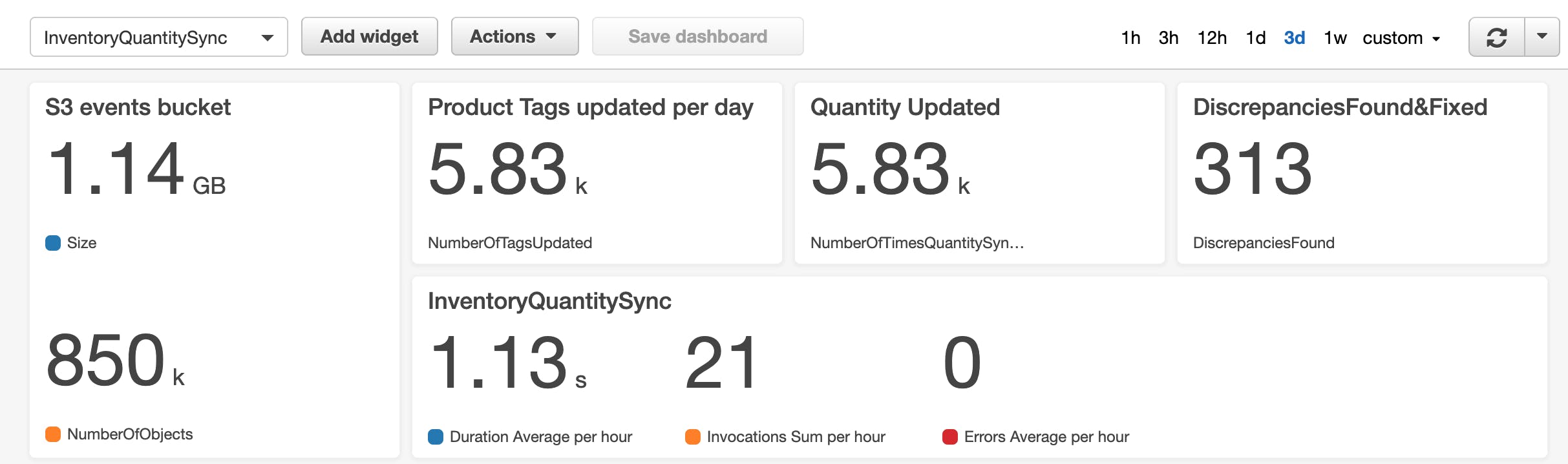
An ability to track events, debug failed transactions and re-process failed events was one of the key features client wanted to implement in his project.
There is a number of production-grade systems that solve these issues, like Jaeger or Epsagon, but a complete serverless and cost-efficiency were key factors, so it was decided to implement in-house solution and integrate it with AWS X-Ray for better visibility.
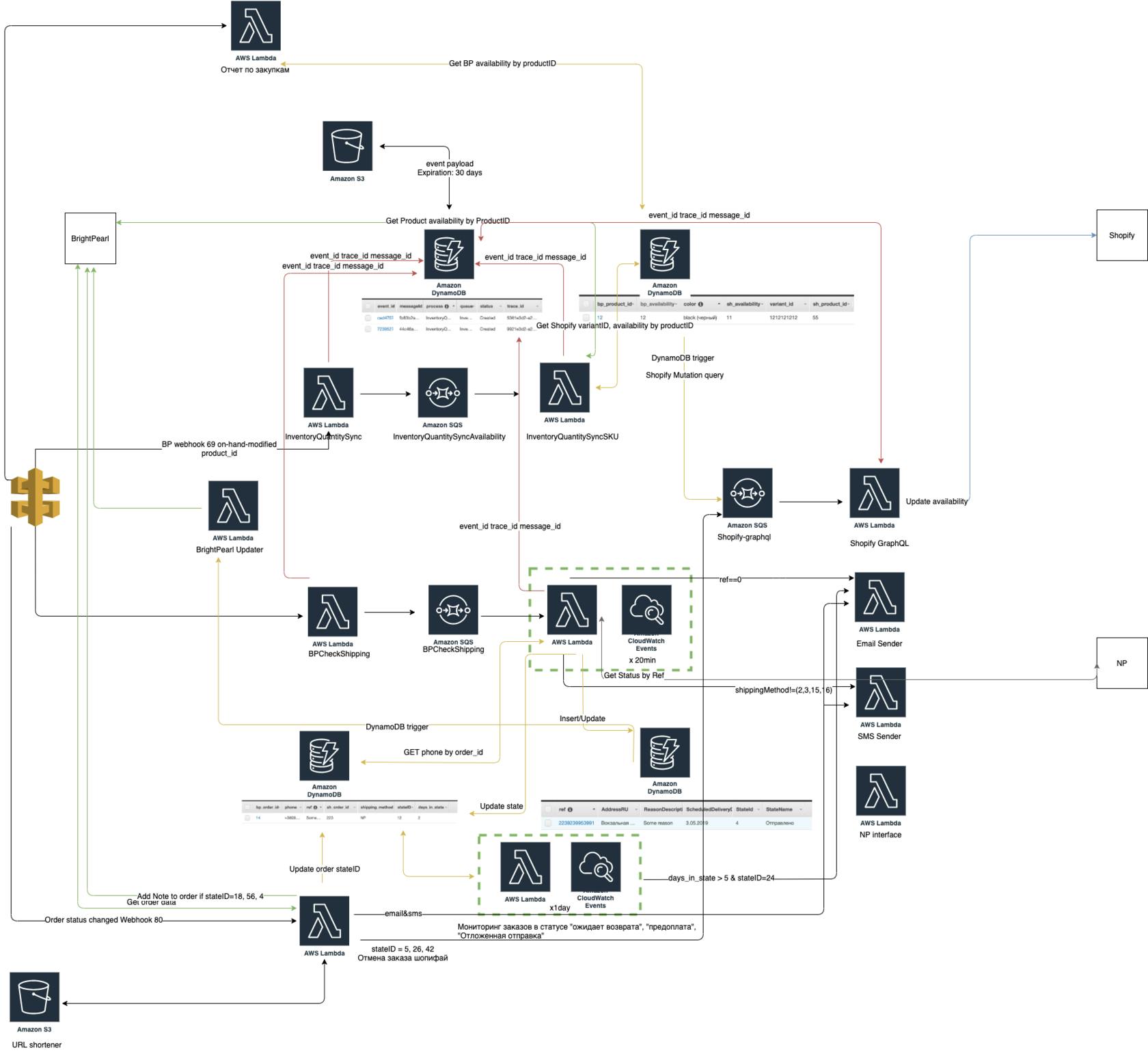
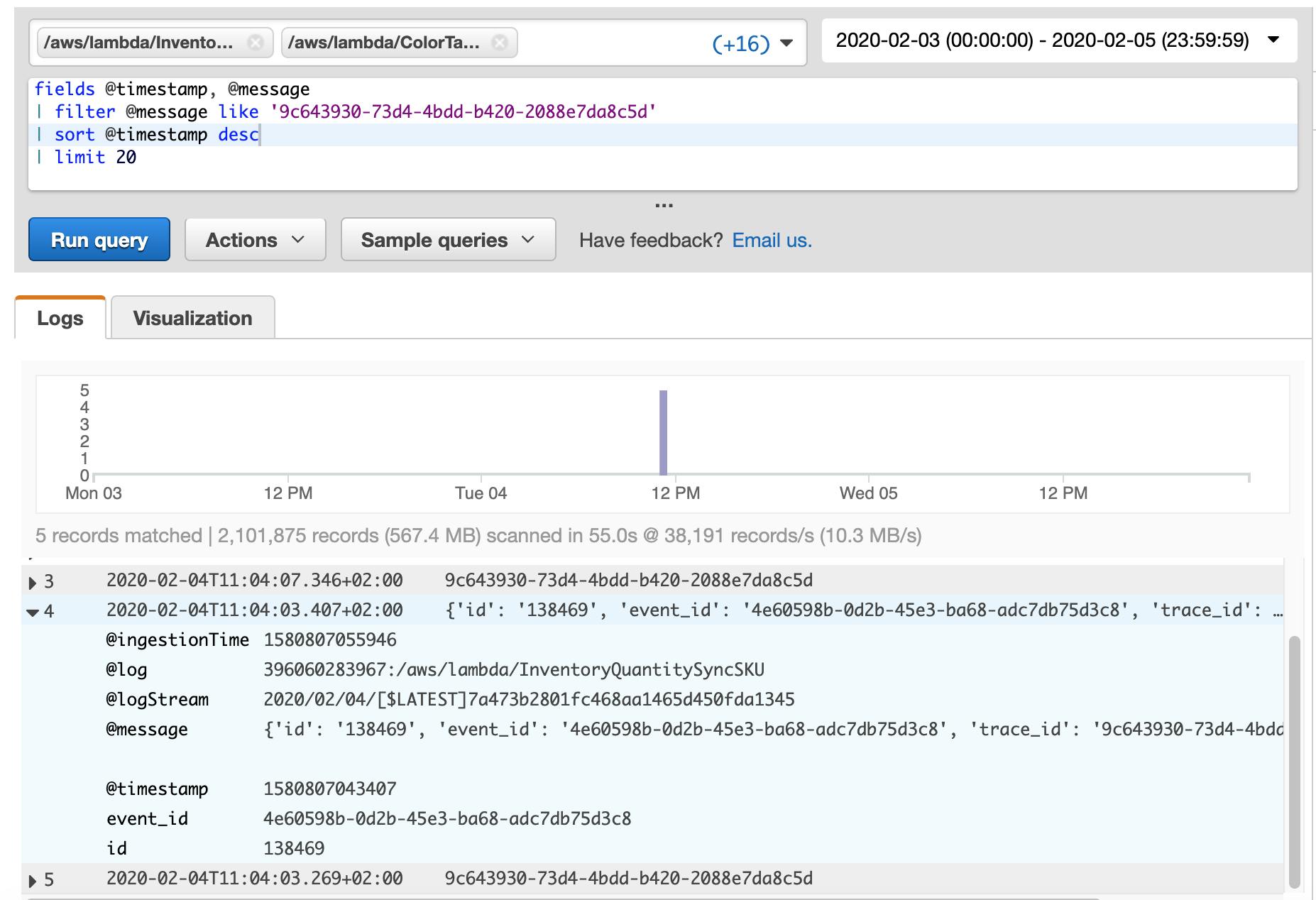
- DynamoDB was chosen to store event data. Initial analysis and discussions with customer discovered that there'll be millions of write requests and very rare read requests mainly caused by the failed transaction investigation. In order to make the setup both cost-efficient and resilient, it was decided to only store a metadata in DynamoDB, which allows to find any information needed.
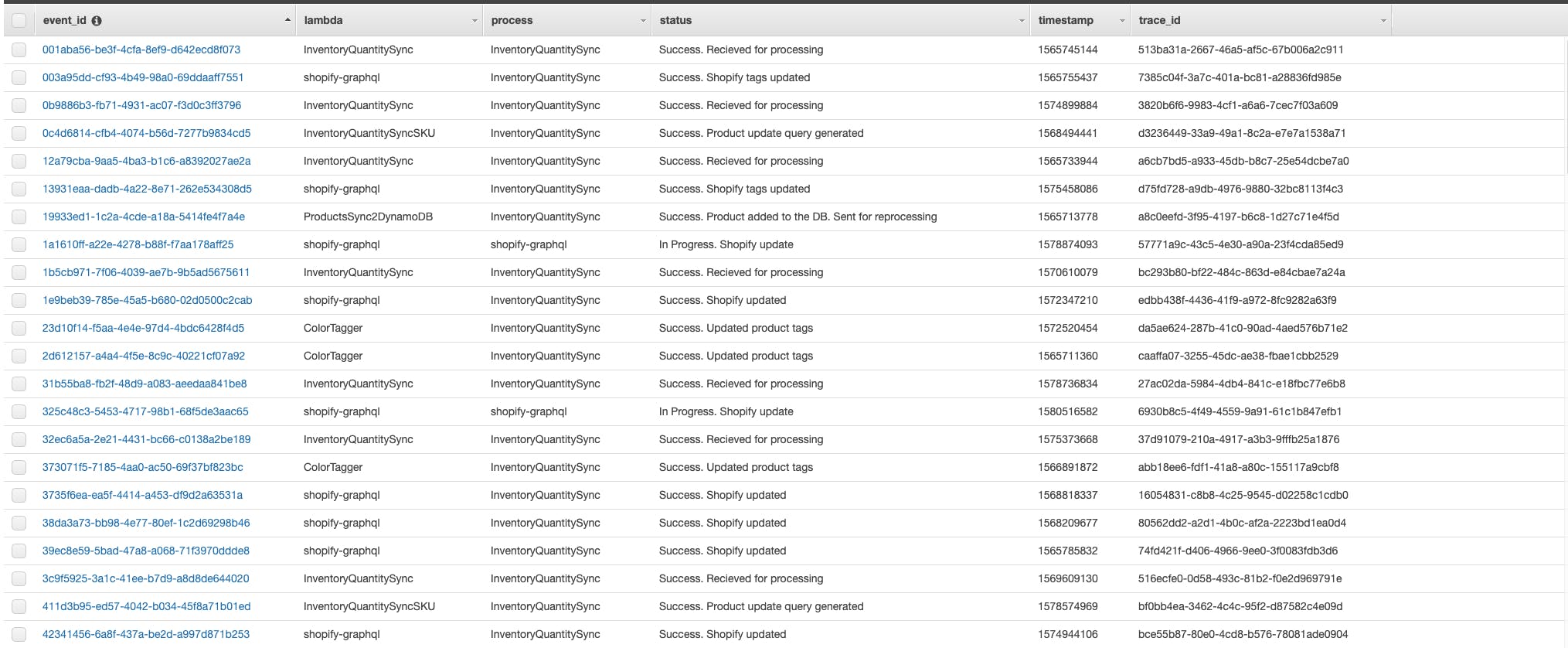
- Event payload was decided to keep at S3 with lifecycle policies, which archives all events older than a month. Considering that event represents a data sync operation, its payload gets stale really quickly and there's no need to keep its payload for years.
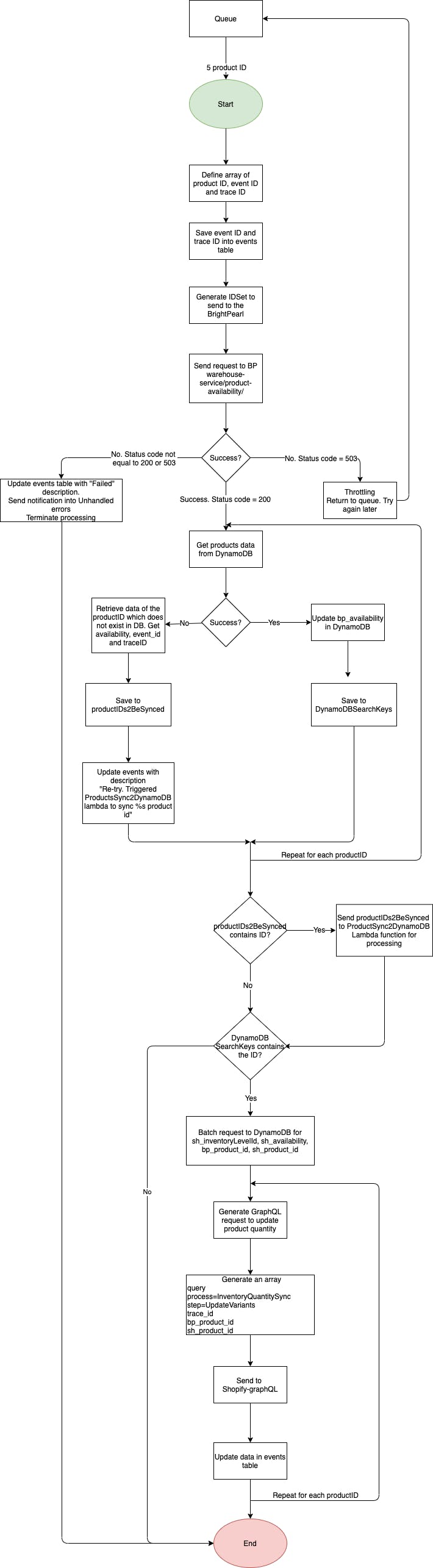
- Each Lambda function inherits a method responsible for event tracking and a method that redefines error handling. This way, Lambda constantly updates DynamoDB table with information on how event processing is going on, and even in case of an exception, it will add details on exception and its cause before terminating and returning an object to the queue.
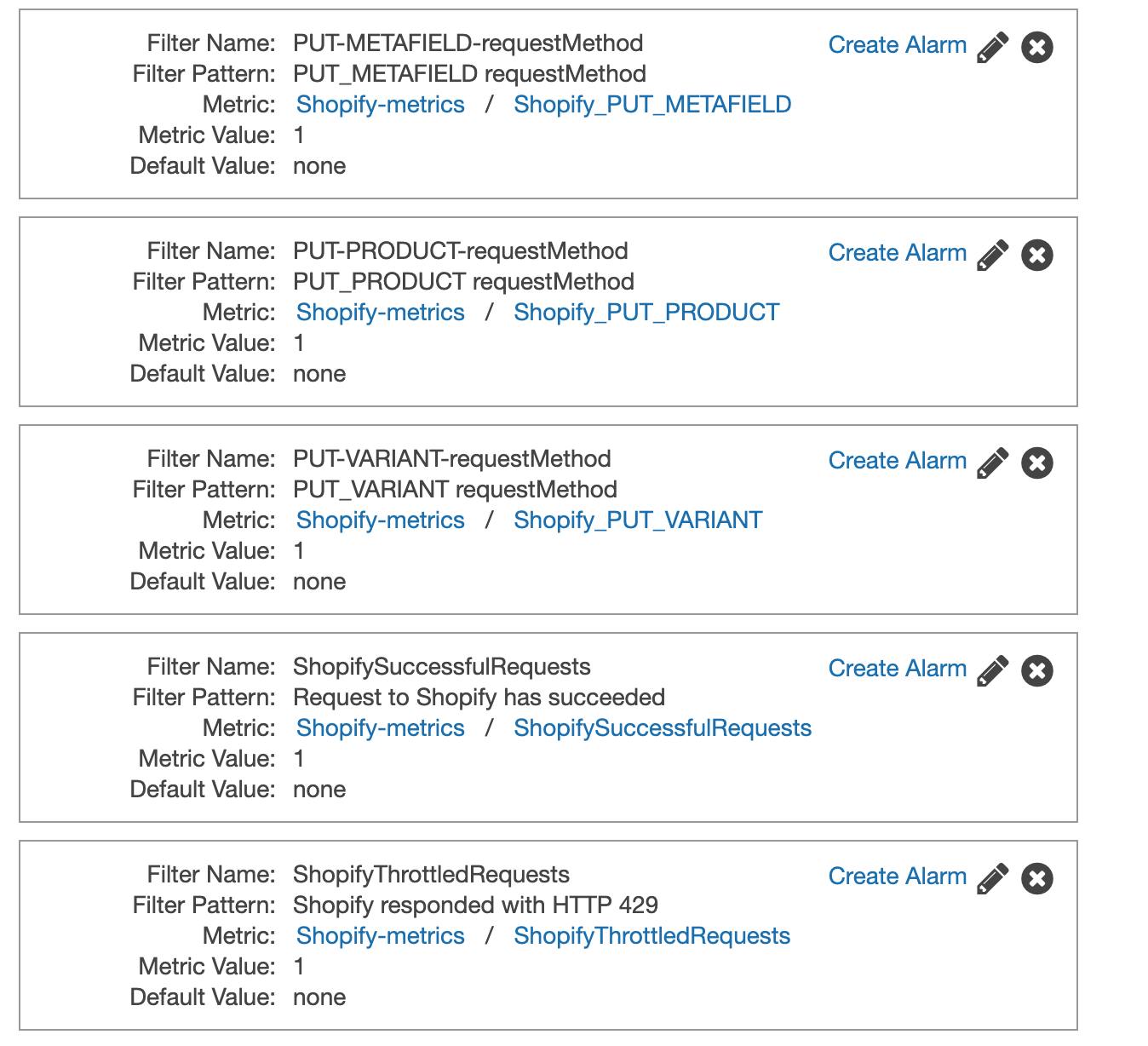
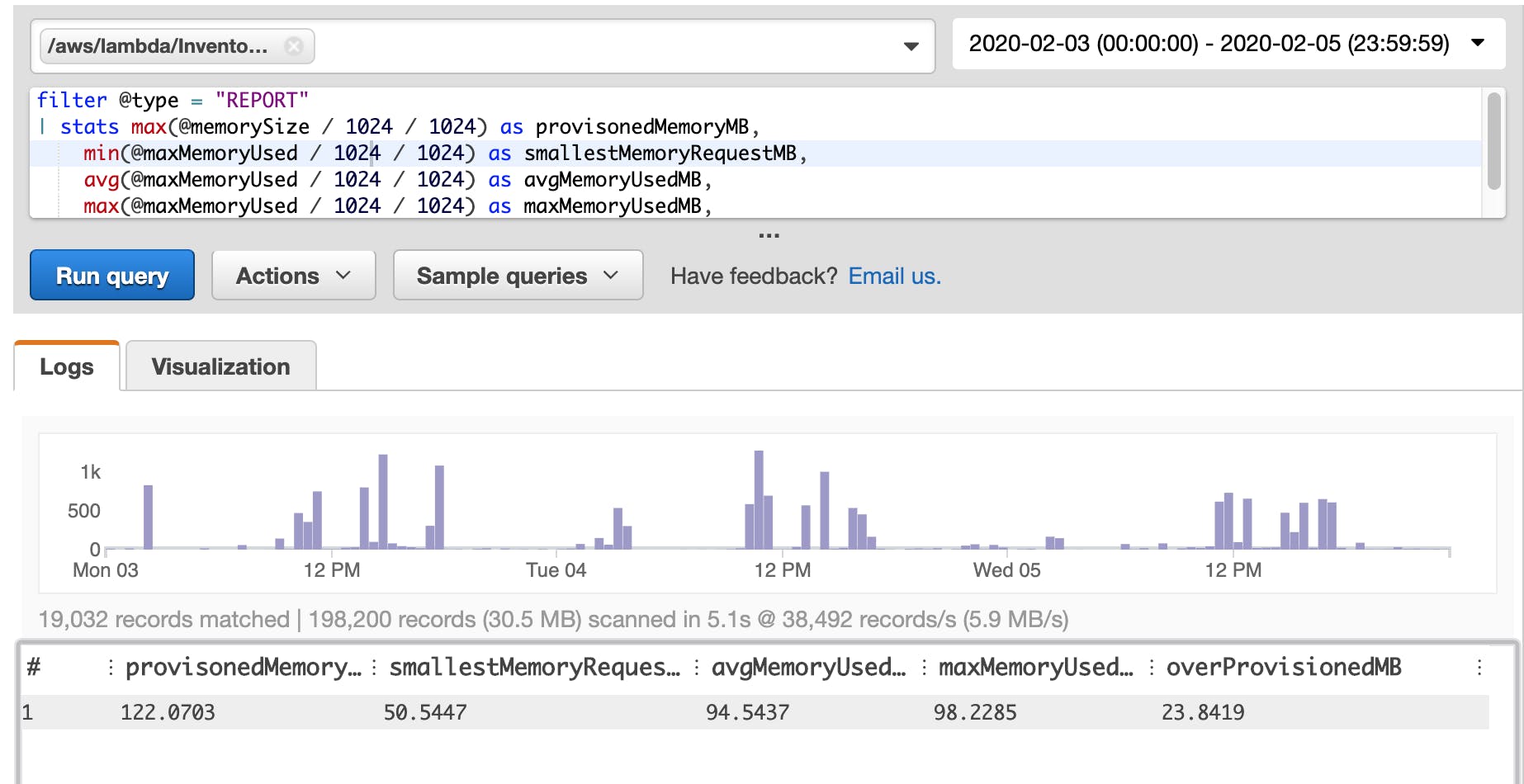
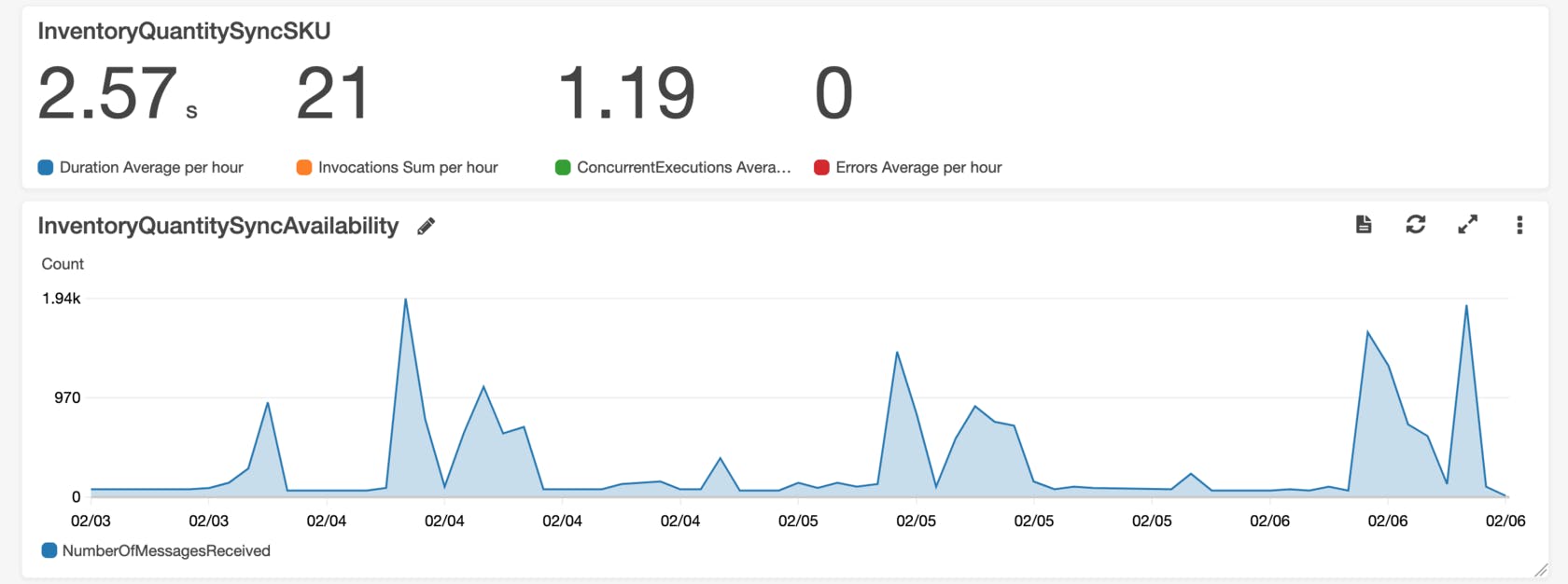
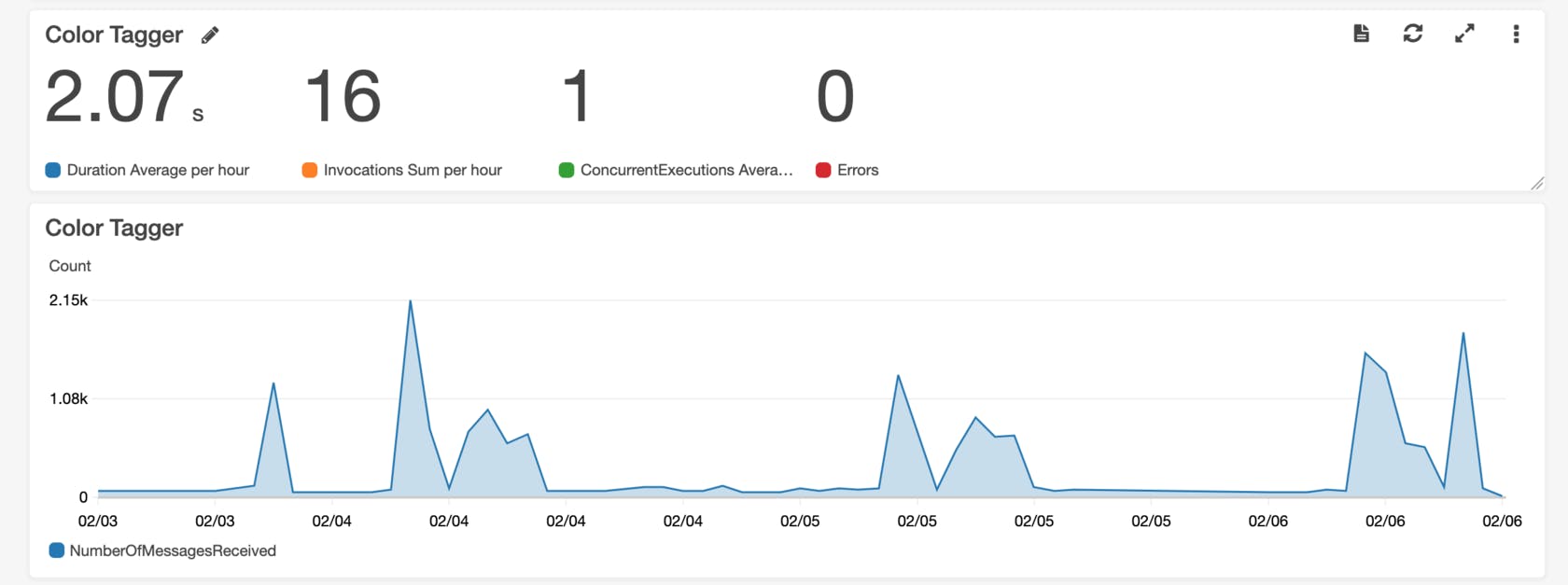
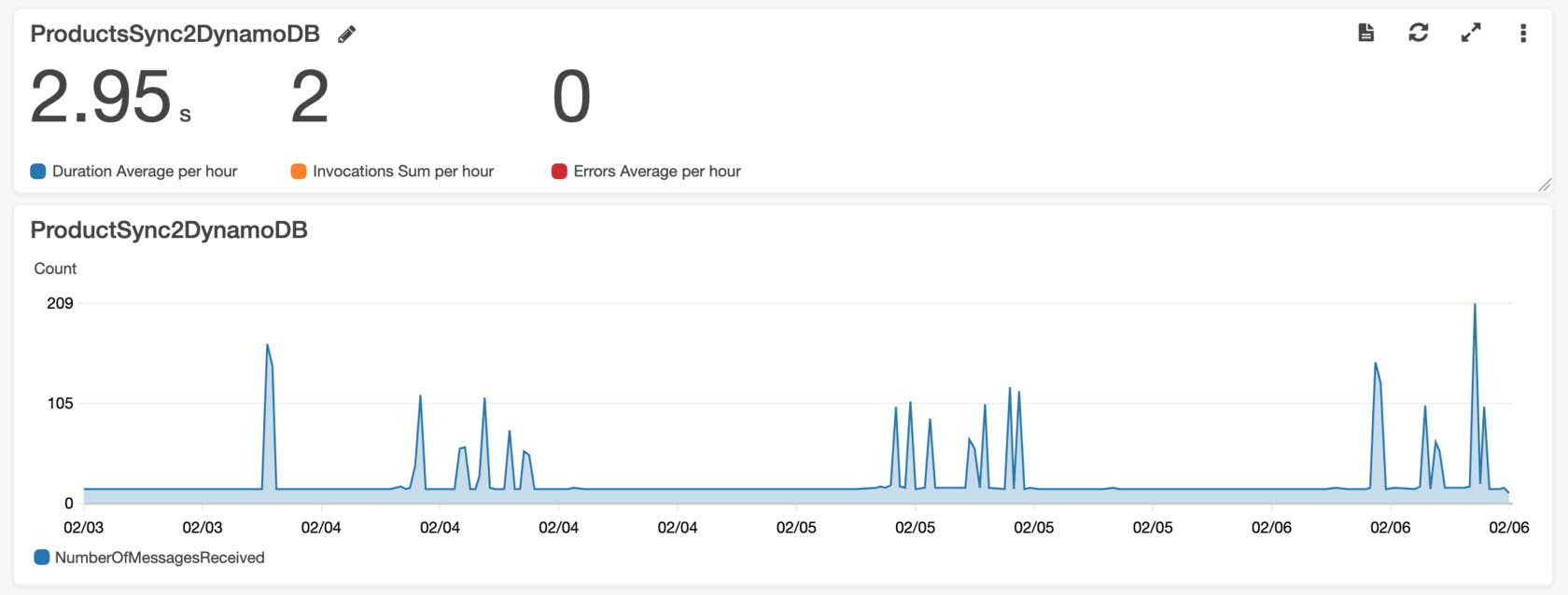
- CloudWatch was used for data tracking, logging and monitoring.
Once event tracking is implemented, it allows to build an event re-processing pipeline around it. With the described above setup, the only thing needed to re-process the whole transaction is event_id. Having event_id, system could search DynamoDB for timestamp and Lambda function name, get event payload from S3, compose an event and send it to Lambda for re-processing.
Automatic re-processing is applied for any case related to the missing information from DynamoDB. For example, if lambda receives a request to sync a product quantity that doesn't yet exist in the database, it will terminate current process and will send product id to another lambda for adding into the database. Once it's added, a job of automatic re-processing will be started.
In some cases, human factor may cause discrepancies between Shopify and BrightPearl data. In order to resolve them right away and not to wait for an automatic event to come and trigger a fix, a lambda function was created. It searches through the database to find product id with different amount of quantity in bp_availability and sh_availability. Once found, a list of product ids are sent to the pipeline entry mimicking the real event














.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max&q=75&w=800&h=533)





